| Table of Contents | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
Introduction
Clustering applies to both JobScheduler Master instances and Agent instances.
The following wording is applied:
- Fail-over indicates an abnormal termination of the current Master/Agent instance and causes the next available Master/Agent instance to take the active role in a cluster.
- Switch-over indicates normal termination of the current Master/Agent instance and causes the next available Master/Agent instance to take the active role in a cluster.
Master Cluster
The following JobScheduler Master cluster types can be configured, depending on the desired behavior:
- The Master Passive Cluster provides fail-over functionality from one active Master instance to one out of a number of standby Master instances.
- The Master Active Cluster makes use of the JobScheduler's Distributed Orders feature to provide load sharing with a number of active Master instances.
The architecture of the Master cluster types is described in the following diagrams:
Note that both types of cluster can be used to provide:
- Cross-Platform Scheduling using Master / Agent Clusters and
- Central Configuration using a Supervisor JobScheduler
Agent Cluster
The following Agent cluster types are available:
- The Agent Passive Cluster implements fixed-priority scheduling: the first Agent is used for any job executions, if the first Agent becomes unavailable then the next Agent is used.
- The Agent Active Cluster implements round-robin scheduling: for each next task the next Agent is used. If an Agent becomes unavailable then it will not be used.
The architecture of the Agent cluster types is explained with the following diagram:
Agent Clusters are a functional layer on top of installed Agents. The same Agent can be a member in any number of Agent Clusters.
For job execution Agent Clusters provide more flexibility than Master Clusters.
Which Cluster Option to choose?
In almost any situation the Master Passive Cluster is the preferable option.
In combination with an Agent Passive Cluster or Active Cluster this offers high availability and scalability at a highly flexible level.
Master Cluster
The following comparison applies to execution of jobs and job chains directly with a Master:
| Passive Cluster | Active Cluster | |
|---|---|---|
| Job Chains | No changes to job chains. | Job chains are configured for use with distributed orders. |
| Requires specification which job chains should be executed on specific servers, for example for log rotation, daily plan calculation etc. | ||
| Jobs | Jobs in a job chain can create temporary files that are picked up by successor jobs. | Each next job is executed on the next Master. Jobs in a job chain cannot rely on the fact that they will be executed on the same Master as their predecessor jobs, for example in case that temporary files are used to pass data between jobs. |
| Database | One transaction per job to store job logs and a single transaction for the order log. | One transaction per job to store the job logs and as many transactions as there are jobs for the order log which will cause higher database load. |
| Database load is increased as there is more overhead for co-ordination of Master instances for execution of next jobs. | ||
| Performance | Vertical scaling: Performance is limited by CPU and memory of a single machine. | Horizontal scaling: Performance is improved if a number of Master instances is used in parallel for task execution. As a performance penalty some overhead for co-ordination of Master instances is required. |
Explanations:
When used with an Agent Cluster then jobs are executed with Agents instead of the Master. This drastically reduces the load on the Master, more precisely there is no noticeable difference in performance between Master Passive Cluster and Master Active Cluster if jobs are executed with Agents.
- The Master Passive Cluster is the preferable choice for most scenarios except for situations when a high load of jobs (>500 parallel tasks) is expected.
- The Master Active Cluster is the preferable choice in a situation only when a larger number of jobs have to be executed with Masters (without using Agents).
Agent Cluster
The following comparison applies to execution of jobs with Agent Clusters:
| Passive Cluster | Active Cluster | |
|---|---|---|
| Jobs | Jobs can create temporary files that are picked up by successor jobs. | Each next job is executed on the next Agent. Jobs cannot rely on the fact that they will be executed on the same Agent as their predecessor jobs, for example in case that temporary files are used to pass data between jobs. |
| Performance | Vertical scaling: Performance is limited by CPU and memory of a single machine. | Horizontal scaling: Performance is improved if a number of Agent instances is used in parallel for task execution. |
Explanations:
- Agents do not know of job chains, they execute jobs only. Job chains and other dependency mechanisms are handled by the Master.
- Agents do not use a database connection.
Cluster Operation
Master Cluster
A fail-over occurs in the following situations when a Master instance is abnormally terminated:
- The machine operating the Master crashes.
- The Master process is killed. Consider that there is no guarantee that processes for running tasks will be killed.
- The Master is aborted
- This operation will kill any running tasks and will abnormally terminate the Master.
- This operation is available from the JOC Cockpit Dashboard and from the command line.
No fail-over occurs in the following situations:
- The machine operating the Master is normally shutdown.
- For Linux operating systems using
systemdorinit.dthe shutdown sequence of services is applied that will normally terminate the Master. - For Windows operating systems the Master Windows Service will receive a stop signal and will normally terminate.
- For Linux operating systems using
- The Master is normally terminated.
- Termination of the Master is delayed until all running tasks are completed.
- This operation is available from the JOC Cockpit Dashboard and from the command line.
GUI Operation
Active Master Operations
The Dashboard offers the following operations for the active Master instance:
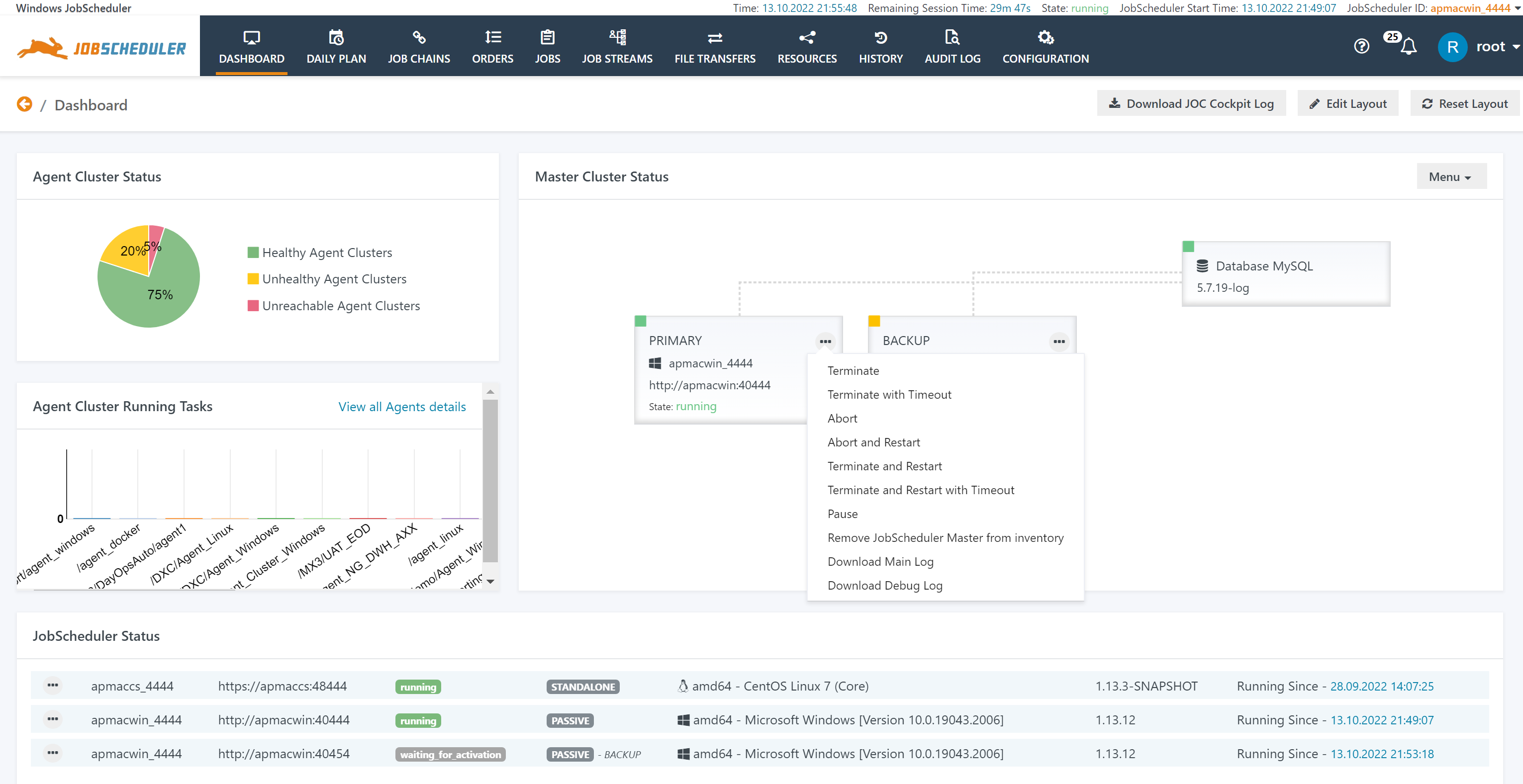
Explanations:
- Normal termination without fail-over
- Terminate: Termination of the Master is delayed until all running tasks are completed.
- Terminate with Timeout: Termination of the Master is delayed until all running tasks are completed or until the timeout is reached and running tasks are killed.
- Terminate and Restart: Same as Terminate but causes the Master to restart.
- Terminate and Restart with Timeout: Same as Terminate with Timeout but causes the Master to restart.
- Abnormal termination with fail-over
- Abort: Kills all running tasks and aborts the Master.
- Abort and Restart: Same as Abort but restarts the Master.
Master Cluster Operations
The Dashboard offers the following cluster operations:
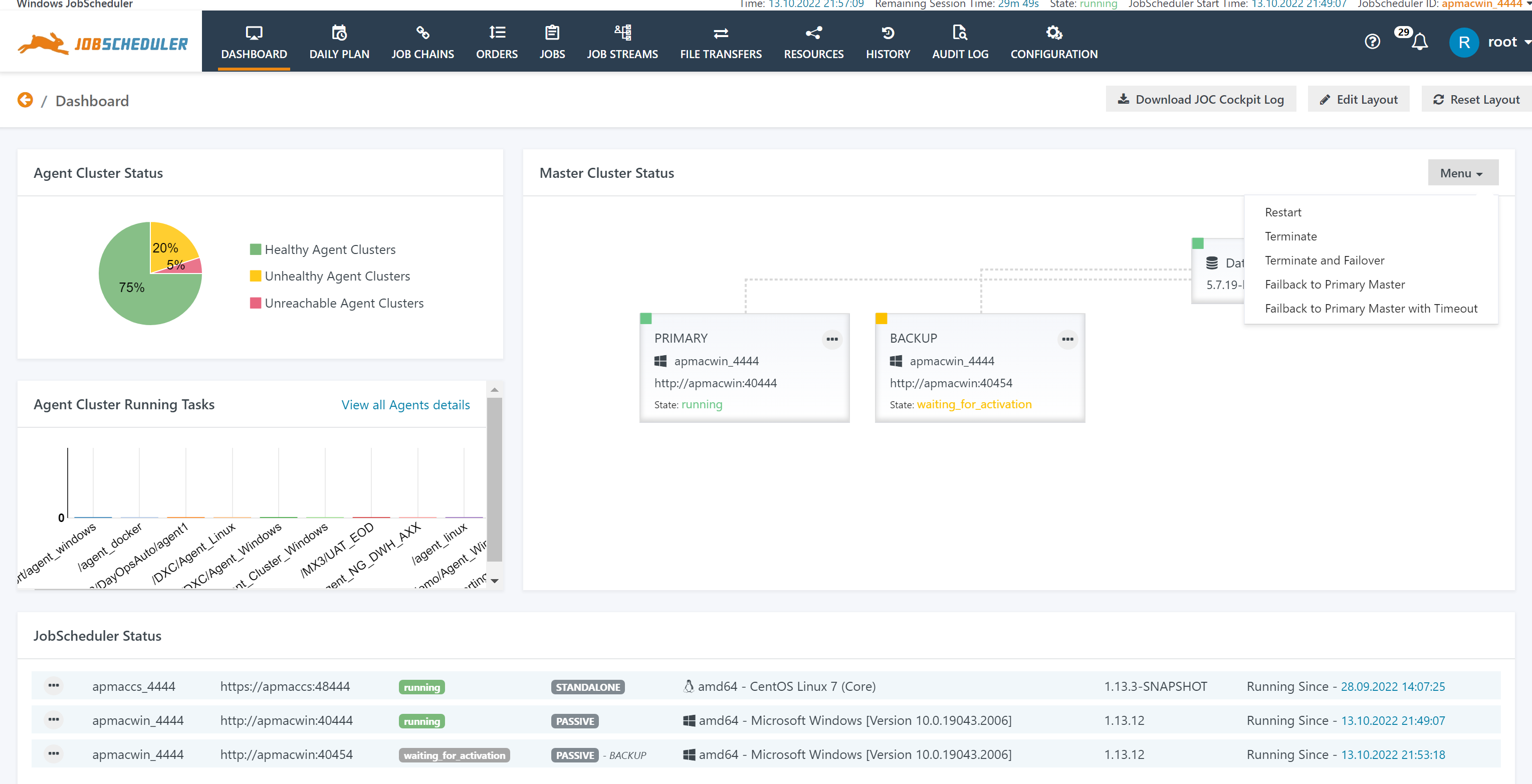
Explanations:
- Normal termination without fail-over
- Restart: Causes all Master instances to be restarted. The active Master retains its role.
- Terminate: Causes all Master instances to be normally terminated. As a result the cluster is down.
- Normal termination with switch-over
- Terminate and Fail-over: The active Master is normally terminated and the standby Master takes the active role.
- Fail-back to Primary Master: If the Backup Master has become active after fail-over then this operation switches roles by normally terminating the Backup Master and causing the Primary Master to take the active role. This operation is delayed until all running tasks are completed.
- Fail-back to Primary Master with Timeout: Same as Fail-back to Primary Master but kills all running tasks that exceed the given timeout.
Command Line Operation
Termination without fail-over / switch-over
The following command line operations normally terminate a Master instance without causing fail-over or switch-over to the next Master instance:
| Code Block | ||
|---|---|---|
| ||
# Terminate all Master instances in a cluster, optionally specifying a timeout in seconds for running tasks
./bin/jobscheduler.sh stop 120 |
| Code Block | ||
|---|---|---|
| ||
@rem Terminate all Master instances in a cluster, optionally specifying a timeout in seconds for running tasks
.\bin\jobscheduler.cmd stop 120 |
| Code Block | ||
|---|---|---|
| ||
@rem Stop Windows Service from the Service Panel or from the command line indicating the Master's Windows Service Name
sc.exe stop sos_scheduler_localhost_4444 |
| Code Block | ||
|---|---|---|
| ||
# Terminate all Master instances in a cluster, optionally specifying a timeout in seconds for running tasks
.\bin\jobscheduler.cmd terminate-cluster 120 |
| Code Block | ||
|---|---|---|
| ||
@rem Terminate all Master instances in a cluster, optionally specifying a timeout in seconds for running tasks
./bin/jobscheduler.sh terminate-cluster 120 |
Explanations:
- A timeout can optionally be specified.
- In Unix environments all running tasks are sent a SIGTERM signal. If the timeout is exceeded then all running tasks are sent a SIGKILL signal. This includes child processes of running tasks.
- In Windows environments the Master waits for running tasks to complete. If the timeout is exceeded then all running tasks are killed. This includes child processes of running tasks.
- Without specifying a timeout the Master will terminate only after all running tasks are completed. The Master does not accept new tasks during this period.
Termination with fail-over
The following command line operations abnormally terminate a Master instance and fail-over to the next Master instance:
| Code Block | ||
|---|---|---|
| ||
./bin/jobscheduler.sh abort |
| Code Block | ||
|---|---|---|
| ||
./bin/jobscheduler.cmd abort |
| Code Block | ||
|---|---|---|
| ||
./bin/jobscheduler.sh kill |
| Code Block | ||
|---|---|---|
| ||
./bin/jobscheduler.cmd kill |
Explanations:
- Abort operation.
- The Master will reliably kill all running tasks and related child processes.
- Kill operation
- It is guaranteed that running tasks are killed, it is not guaranteed that child processes of running tasks are killed.
Termination with switch-over
The following command line operations normally terminate a Master instance and switch-over to the next Master instance:
| Code Block | ||
|---|---|---|
| ||
# Terminate Master instance and optionally specify a timeout in seconds for tasks to complete before being killed
./bin/jobscheduler.sh terminate-fail-safe 120 |
| Code Block | ||
|---|---|---|
| ||
@rem Terminate Master instance and optionally specify a timeout in seconds for tasks to complete before being killed
.\bin\jobscheduler.cmd terminate-fail-safe 120 |
Explanations:
- A timeout can optionally be specified.
- In Unix environments all running tasks of the Master are sent a SIGTERM signal. If the timeout is exceeded then all running tasks are sent a SIGKILL signal. This includes child processes of running tasks.
- In Windows environments the Master waits for running tasks to complete. If the timeout is exceeded then all running tasks are killed. This includes child processes of running tasks.
- Without specifying a timeout the Master will terminate only after all running tasks are completed. The Master does not accept new tasks during this period.
Agent Cluster
Agent Clusters do not make use of the distinction between fail-over and switch-over. In fact the Master chooses the next available Agent if an Agent becomes unavailable.
A fail-over/switch-over occurs in the following situations:
- Abnormal Termination
- The machine operating the Agent crashes.
- The Agent process is killed.
- The Agent is aborted
- This operation will kill any running jobs and will abnormally terminate the Master.
- This operation is available from the command line.
- Normal Termination
- The machine operating the Agent is normally shutdown.
- For Linux operating systems using
systemdorinit.dthe shutdown sequence of services is applied that will normally terminate the Agent. - For Windows operating systems the Agent Windows Service will receive a stop signal and will normally terminate.
- For Linux operating systems using
- The Agent is normally terminated.
- Termination of the Agent is delayed until all running tasks are completed.
- This operation is available from the command line.
- The machine operating the Agent is normally shutdown.
GUI Operation
No GUI operations are available as due to the architecture JOC Cockpit does not have direct access to Agents. Instead, Agents are controlled by the Master only.
Command Line Operation
Normal Termination
The following command line operations normally terminate an Agent instance. The operation is delayed until all running tasks are completed.
| Code Block | ||
|---|---|---|
| ||
# The Agent Start Script is used with its default value for the Agent port (4445) and optionally specifying a timeout for running tasks
./bin/jobscheduler_agent.sh stop 120
# The Agent Instance Script is used specifying a distinct port and optionally specifying a timeout for running tasks
./bin/jobscheduler_agent_<port>.sh stop 120 |
| Code Block | ||
|---|---|---|
| ||
@rem The Agent Start Script is used with its default value for the Agent port (4445) and optionally specifying a timeout for running tasks
.\bin\jobscheduler_agent.cmd stop 120
@rem The Agent Instance Script is used specifying a distinct port and optionally specifying a timeout for running tasks
.\bin\jobscheduler_agent_<port>.cmd stop 120 |
Explanations:
- A timeout can optionally be specified.
- In Unix environments all running tasks are sent a SIGTERM signal. If the timeout is exceeded then all running tasks are sent a SIGKILL signal. This includes child processes of running tasks.
- In Windows environments the Agent waits for running tasks to complete. If the timeout is exceeded then all running tasks are killed. This includes child processes of running tasks.
- Without specifying a timeout the Agent will terminate only after all running tasks are completed. The Agent does not accept new tasks during this period.
Abnormal Termination
The following command line operations abnormally terminate an Agent.
| Code Block | ||
|---|---|---|
| ||
# The Agent Start Script is used with its default value for the Agent port (4445)
./bin/jobscheduler_agent.sh abort
# The Agent Instance Script is used specifying a distinct port
./bin/jobscheduler_agent_<port>.sh abort |
| Code Block | ||
|---|---|---|
| ||
@rem The Agent Start Script is used with its default value for the Agent port (4445)
.\bin\jobscheduler_agent.cmd abort
@rem The Agent Instance Script is used specifying a distinct port
.\bin\jobscheduler_agent_<port>.cmd abort |
| Code Block | ||
|---|---|---|
| ||
# The Agent Start Script is used with its default value for the Agent port (4445)
./bin/jobscheduler_agent.sh kill
# The Agent Instance Script is used specifying a distinct port
./bin/jobscheduler_agent_<port>.sh kill |
| Code Block | ||
|---|---|---|
| ||
@rem The Agent Start Script is used with its default value for the Agent port (4445)
.\bin\jobscheduler_agent.cmd kill
@rem The Agent Instance Script is used specifying a distinct port
.\bin\jobscheduler_agent_<port>.cmd kill |
Explanations:
- Abort operation.
- The Agent will reliably kill all running tasks and related child processes.
- Kill operation
- It is guaranteed that running tasks are killed, it is not guaranteed that child processes of running tasks are killed.
Cluster Configuration
Master Cluster
- Two or more Master instances Two or more JobSchedulers can be operated as a cluster.
- All JobSchedulers Master instances in a cluster cluster have to:
- be identified by the same JobScheduler ID and
- have to use the same database.
- Furthermore, each JobScheduler Master in a cluster has to be started with one of the following cluster options:
-exclusive-exclusive -backup-distributed-orders
- See http://www.sos-berlin.com/doc/en/scheduler.doc/command_line.xml for more information about JobScheduler start Master startup options.
- The following types of JobScheduler Master clusters can be configured, depending on the cluster start startup options used.
JobScheduler Cluster
JobScheduler Passive Cluster
...
Master Passive Cluster
- We assume a Primary JobScheduler Master with the start option
-exclusive. - Backup JobSchedulers Masters will use the start options:
-exclusive-backup-backup-precedence=n- where
nis a number. - The option
-backup-precedenceis optional and the numberndefines the order in which the Backup JobSchedulers Masters become active.
- where
- Exclusively the The Primary JobScheduler Master exclusively will be active once all the JobSchedulers Master instances have been started.
- All JobSchedulers Masters in the cluster use the same configuration (jobs, job chains, orders, etc.).
- A Backup JobScheduler Master will not become active if the Primary JobScheduler Master terminates in a normal way.
- If the Primary JobScheduler Master is aborted or its process is killed (e.g. the server crashes) then the (next) Backup JobScheduler Master will become active and will be aware of the job states and order states. That is, the 'new' JobScheduler Master will be aware of whether
- jobs or job chains are stopped or active,
- job chain nodes are stopped, skipped or active,
- orders are suspended or active and
- what their current state is.
- The Backup Master waits ca. 130 seconds to be certain that the Primary Master is down before it becomes active.
- All starts of jobs and orders that would take place within this time will be lost, the jobs and orders will run at the next scheduled time.
- If a Backup JobScheduler Master is active and the primary JobScheduler Primary Master is restarted then the Backup JobScheduler Master has to be terminated in order to reactivate re-activate the Primary JobSchedulerMaster.
See also
JobScheduler Active Cluster
Load Balancing Cluster
Change Management References
| Jira | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
Master Active Cluster
- All Masters in this cluster use the start option All JobSchedulers in this type of cluster use the start options
-exclusive -distributed-orders. - All the JobSchedulers Masters in this type of cluster will be active once they all have been started.
- Each JobScheduler of Master in this cluster will handle its own jobs independently, with the exception of orders for job chains that are configured as distributed.
- Distributed orders Orders are handled in way that each cluster member can process any step of an order within a job chain. Cluster members use some a load balancing sharing logic to determine which JobScheduler Master instance should process the next job for an order in a job chain based on the number of tasks currently running with each Master.
See also
Jira server SOS JIRA columns key,summary,type,created,updated,due,assignee,reporter,priority,status,resolution serverId 6dc67751-9d67-34cd-985b-194a8cdc9602 key JS-1177 Jira server SOS JIRA columns key,summary,type,created,updated,due,assignee,reporter,priority,status,resolution serverId 6dc67751-9d67-34cd-985b-194a8cdc9602 key JOC-48 Jira server SOS JIRA columns key,summary,type,created,updated,due,assignee,reporter,priority,status,resolution serverId 6dc67751-9d67-34cd-985b-194a8cdc9602 key JS-1251 - http://www.sos-berlin.com/doc/en/scheduler.doc/distributed_orders.xml and
- and http://www.sos-berlin.com/doc/en/scheduler.doc/xml/job_chain.xml#attribute_distributed
Change Management References
| Jira | |||||||
|---|---|---|---|---|---|---|---|
|
...
|
How to set cluster start options
- You can set cluster options during installation of the JobSchedulerMaster.
- After the installation has been completed, the cluster options can be set by editing the Edit the ./bin/jobscheduler_environment_variables file.(sh|cmd). as described below to change the cluster options after installation has been completed and the cluster has been made operational:
Unix
stop the JobScheduler Master
edit ./bin/jobscheduler_environment_variables.sh
Code Block language bash SCHEDULER_CLUSTER_OPTIONS=-exclusive
- start the JobSchedulerMaster
Windows
- stop the JobScheduler serviceMaster Windows Service
remove the JobScheduler serviceMaster Windows Service
Code Block language bash .\bin\jobscheduler.cmd remove
modify .\bin\jobscheduler_environment_variables.cmd
Code Block language bash SET SCHEDULER_CLUSTER_OPTIONS=-exclusive
install the JobScheduler serviceMaster Windows Service
Code Block language bash .\bin\jobscheduler.cmd install
- start the JobScheduler Master service
- See also JobScheduler Installation Manual
The cluster tab in JOC
If you open the JobScheduler Operating Center (JOC) of a JobScheduler which is member of a cluster then a Cluster tab will be displayed, showing the cluster members.
Agent Cluster
See JobScheduler Universal Agent - Installation & OperationExample: Backup Cluster:
